Estimating seems easy, but getting estimations right continuously in software development is incredibly hard. In this article, we tell you why estimations often fail and how to identify the right process for you and produce better estimates.
A quick intro on Terminology
Let’s first start with a brief definition of the terms used in this article: Estimation, estimate, and measurement.
An estimate is an approximated value of the estimated property, e.g., the time it takes to finish a development task.
The process of finding an estimate is called estimation and the act of doing it estimating.
Depending on what we are interested in, the value might be of different scales:
- ordinal scale, where we know the order but not the distance between the estimated values (small, medium, high effort),
- interval scale, where we additionally know the distance between the values (ten story-points is twice as much as five story-points),
- rational scale, where we also know the absolute zero (man-days effort, 1000 Dollars of equipment).
With a statistical approach, we would use sampling to derive a value from an underlying population based on its statistic. In software development, we usually lack structured data since each development task is unique to some degree, so we can’t just build statistics based on similarity to previous tasks.
But information is still available through software development experts’ experience: The expert decomposes the development task until he finds similar components with know size and aggregates the component values to estimate the task, a process called fermi decomposition.
Estimates are always an approximation of the “real” parameter since we derive them from incomplete information. If we can extract an exact value from available data, we call it measurement.
Estimating in software development is a challenge, mostly because of unclear targets and expectations resulting in an inappropriate choice or inconsistent execution of a methodology. Without clear requirements, we won’t be able to assess the quality of the estimates, which leads to project risks through wrong projections.
Why is it so hard to get high-quality estimations?
Several root causes are leading to low-quality estimations. The following list contains conclusions from my own experience. It enumerates what we perceive as the most frequent and damaging sources of wrong estimates. Proposals for additional root causes are very welcome!
Low-quality requirements will lead to wrong estimations inevitably. Development teams often see themself urged to estimate based on half-backed specifications early in the project with the assertion that this is just a first sizing attempt. But usually, these low-quality estimations survive, causing delays and frictions. Developers will counteract by adding buffers, further decreasing the accuracy of their estimates.
Dependencies and effort vs. duration estimations
There is an inherent conflict between the need to financially size a project and the planning of project milestones and delivery targets. The effort required to finalize a work package is rarely equal to the time needed to deliver it due to its dependencies. The work in progress (WIP), as the summary of started but not finished tasks, is a mix of items actively worked on and things blocked due to dependencies. Only in the rare case where there are no dependencies at all effort will be equal to duration.
Not the right team members involved in estimating
Having the right composition of team members is key to high-quality estimations. But this is not trivially solved in a real-world project. In the early phases of the project, the team might not yet be fully available. We might even have changing teams due to different organizational functions throughout the stages of the project.
Especially in the early phases of a project, the available information to do accurate estimations is partially missing or incomplete. Furthermore, the team does not yet understand the problem domain and the technical challenges well enough.
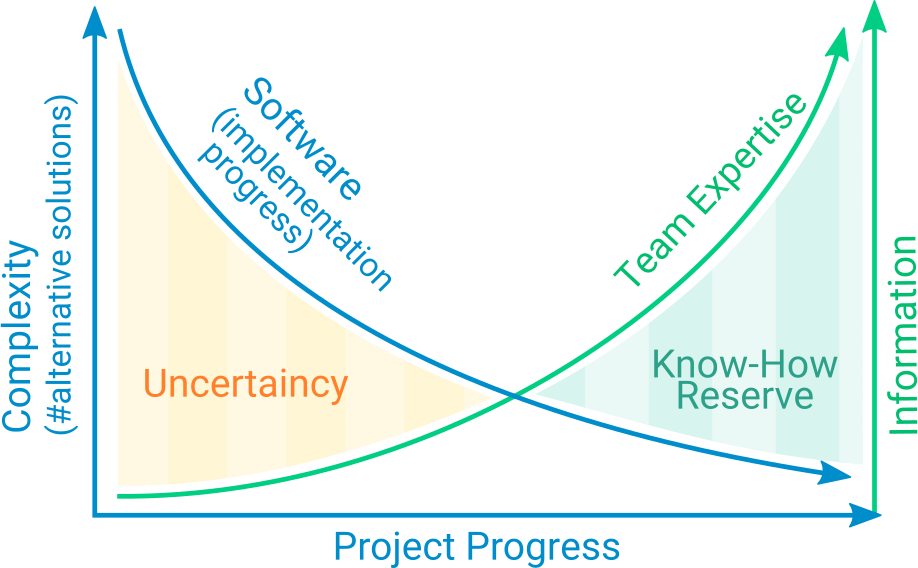
Nevertheless: No matter how thin the available information is, every proper estimation increases the project’s predictability. The genuine risk is that early estimates stay, although they could be reevaluated, resulting in a reduced variance and higher predictive quality.
Are there any existing solution attempts?
There are several different proposals on how to address estimation inaccuracy. Let’s first try to get an overview of the most prominent methodologies.
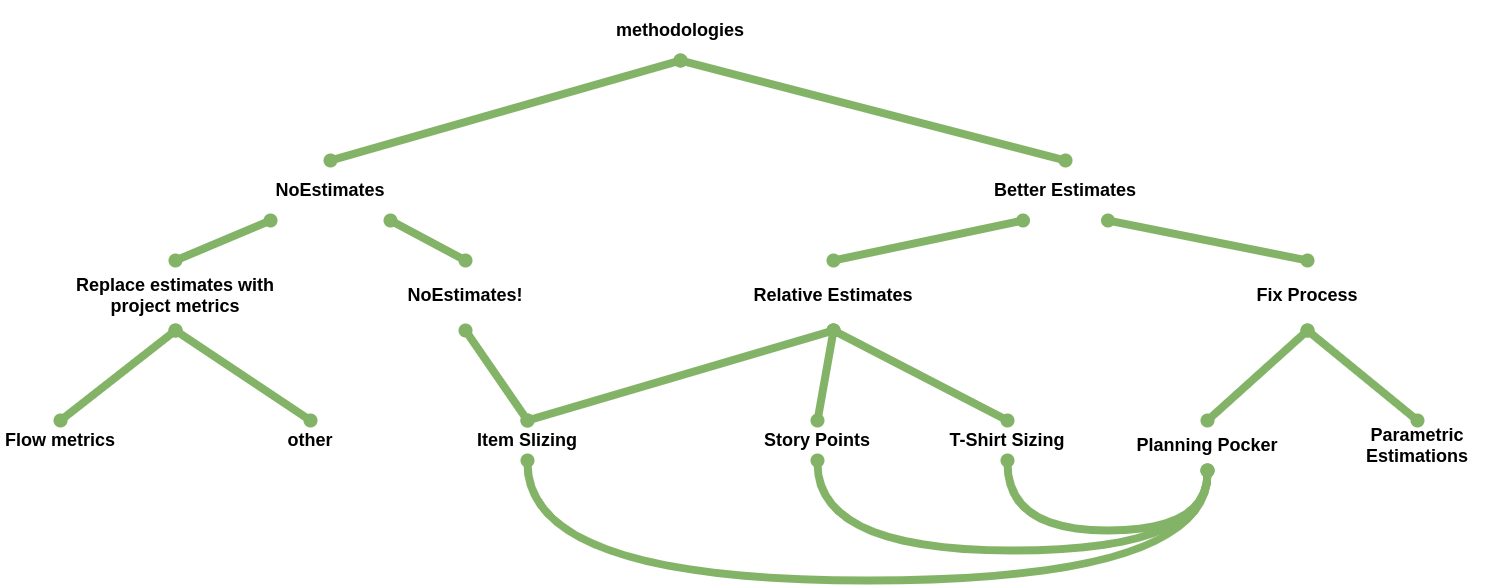
NoEstimates advocates criticize that estimates in projects are meaningless since projects are always dealing with something new, which can’t be adequately estimated. In their view, project teams estimate because it is common practice, not because they believe in them. The propagated solution is item slicing: Tickets get sliced until they are all equally sized. Project forecasts will be done based on the delivery rate. The Kanban community promotes project forecasts based on flow-based metrics like throughput and duration.
The relative estimation approach drops estimations on a rational scale (required man-months) in favor of estimates on an interval scale (compared to a reference element, e.g., story points) or on an ordinal scale (t-shirt size). This approach supports trend analysis by measuring how long it took to resolve the work-packages and calculating trends without the need for exact value estimates.
Process-oriented approaches attempt to increase the estimation quality by defining clear conditions and setups to guarantee proper execution.
- Planning poker: Planning poker is a gamification approach of estimation sessions where a team of estimators follows an iterative process of blind estimating with cards on a Fibonacci scale until the team agrees on one final estimate for each development task.
- Parametric estimations: Based on an analysis of past projects the parametric estimations methods derive a calculations model that can be used to calculate project metrics (e.g. size, effort). Experts analyze the new project based on the parameters defined by the calculation model (e.g. number of components, the complexity of data model, the number of public API services) which are then used to perform the calculation.
From our experience, most organizations do not follow a structured approach to analyze their requirements towards estimations and often alternate between different methodologies depending on the loudest voice, hip trends, and changing decision-makers.
We always estimate! But the chosen methodology will determine the available forecasting and prediction capabilities!
So, is the problem already solved? We don’t think so. All outlined solution attempts to the estimations conundrum have unique tradeoffs. For example, I’m a big supporter of Kanban, and using Kanban flow-metrics as project predictors is an excellent data-driven approach. Nevertheless, it is not very helpful in doing initial project sizing and planning or project calculations. Treating all projects as agile projects that won’t need any upfront cost calculations or delivery milestones is, in my opinion, an oversimplification. Even for the extreme case of purely internal research and development projects, without external deadlines, you need some data to decide on your innovation pipeline (e.g. sizing vs. available capacity, expected return on investment, complexity). You will always have to tailor the solution you choose to your context-specific needs.
It’s important to realize that, no matter what approach you choose, you will always estimate. NoEstimates is suggesting that there won’t be any estimates, but this is grossly misleading. By trying to slice work into equally sized tickets, as promoted by the NoEstimates methodology, you need to assess the size, which is an act of estimating.
You first need to evaluate and define the forecasting and prediction capabilities required for your project and, secondly, design a process that delivers the required data.
So, what’s our proposed approach?
The estimations’ usefulness heavily depends on building a clear strategy.
We first need to define:
- Why we estimate: Before we do any estimations, we will have to understand and define what decisions will be informed based on the data we collect. Always only collect data that will relevant to make project decisions.
- How we estimate: To get measurable and consistent quality, we need a rigid process. Otherwise, estimations will suffer from high variance, will not be comparable, and therefore will be an insufficient basis for analysis, project calculations, and predictions.
- When we estimate: The requirements towards estimations change with the project maturity. In the early phases of a project, you may need a different methodology, estimation unit, and estimator team compositions than in later stages. Don’t fall into the trap of oversimplification by following a trend dogma on estimation best practice.
And establish a practice to:
- Measure quality: Use a scientific approach to measure the quality of your estimation. The quality of the estimates is not static and will change over a project’s lifecycle (e.g., by your team’s growing know-how). You must understand the standard deviations and confidence intervals of your estimates. Additionally, I’d recommend tracking metrics that give feedback on process quality, e.g., the size and the representativeness of the estimating teams.
- Continuously refine: As the information grows, the estimations’ variance will decrease. Ensure you use estimation quality measures to regularly reevaluate the lowest-quality data to increase overall analytic and predictive power, reducing project delivery risks.
- Replace estimation with measurements: In the early stages of a project, estimating is usually the only available approach to gather project data for planning and commitments. In later phases, some of the estimations can be supplemented or even substituted by measurements. Typical examples are to use work time reports to adjust effort estimations or lead time histograms as a substitute for duration estimations.
- Calibrate your team: Establish feedback loops that help your team assessing their estimation performance and continuously calibrate to become better estimators. Train your team’s estimation skills to replace experts’ intuition with structured approaches like fermi decomposition to better deal with uncertainty and to achieve more consistent estimation results.
This is the first of an upcoming series of articles where my colleagues from Datarocks and myself will do deep dives to establish the theoretical background and define an estimations strategy that supports gathering actionable data and metrics as the base for sound project decisions.
We want to invite you to share your own experience, challenges, or success stories. Please don’t hesitate to ask questions or propose topics of interest to you. We will cover as many as possible in this series.